Java中的虚拟线程
Java在 JDK 19 中引入了虚拟线程。经过几轮预发布后,最终在 JDK 21 中确定了下来。它是一个非常重要的特性,能够让我们以简单的方式编写高吞吐量的IO密集型应用。
虚拟线程的引入是Java在并发模型上的一次重大飞跃,标志着Java对传统线程模型的根本性改进,使其能够与Go和Node.js等语言一样,处理大规模的并发任务,但同时保持Java的强大特性和生态系统兼容性。
从IO密集型任务说起
最近,小明遇到了一个棘手的需求:他需要从电脑上读取300个文件,再将文件中的所有内容进行综合分析。为了简化任务模型,我们省略了其中的分析功能,并假设读取每个文件平均需要50ms。这是一个典型的IO密集型任务,小明决定使用传统线程池来进行处理。他写下了第一版Java代码:
long startTime = System.currentTimeMillis();
var executor = Executors.newFixedThreadPool(10);
IntStream.range(0, 300).forEach(i -> {
executor.submit(() -> {
System.out.println(Thread.currentThread() + ": 处理任务:" + i);
try {
Thread.sleep(50); // 模拟任务执行
} catch (InterruptedException e) {
e.printStackTrace();
}
});
});
executor.shutdown(); // 关闭线程池
try {
// 等待所有任务执行完成
if (!executor.awaitTermination(1, TimeUnit.MINUTES)) {
executor.shutdownNow();
}
} catch (InterruptedException e) {
executor.shutdownNow();
}
long endTime = System.currentTimeMillis();
System.out.println("任务执行完成,总花费时间: " + (endTime - startTime) + " 毫秒");如果采用单线程读取300个文件,任务一共需要耗费15s。聪明的小明使用了一个具有10个线程的线程池。这样,大约只需要1.5s就可以完成同样的任务,效率足足提高了10倍。
小明是一个爱思考的好孩子, 他又想,既然有300个文件,那么,开启300个线程,岂不是可以将吞吐量达到最大呢?
想法很好,但在Java中启动线程的成本是很昂贵的。一个线程需要几千条 CPU 指令才能启动,并且会消耗几兆字节的内存。同时,如果线程数过多,CPU 也会因为频繁的线程切换(thread switching)而导致性能下降。
平台线程和虚拟线程
小明就想,既然传统线程成本昂贵,如果能有一种成本很低的线程就好了。这种成本很低的线程就是本文说的虚拟线程。
1995年Java 1.0发布时,其中就包括 java.lang.Thread,它为我们提供了对操作系统线程(OS线程)的抽象,称之为“平台线程(platform thread)”,平台线程在底层 OS 线程上运行 Java 代码,并在代码的整个生命周期中占用该 OS 线程,因此平台线程的数量受限于 OS 线程的数量。
线程是需要被调度分配相应的CPU时间片的。对于平台线程,JDK依赖于操作系统中的调度程序;而对于虚拟线程,JDK先将虚拟线程分配给平台线程,然后平台线程按照通常的方式由操作系统进行调度。
下面是OS线程、平台线程和虚拟线程的关系图:
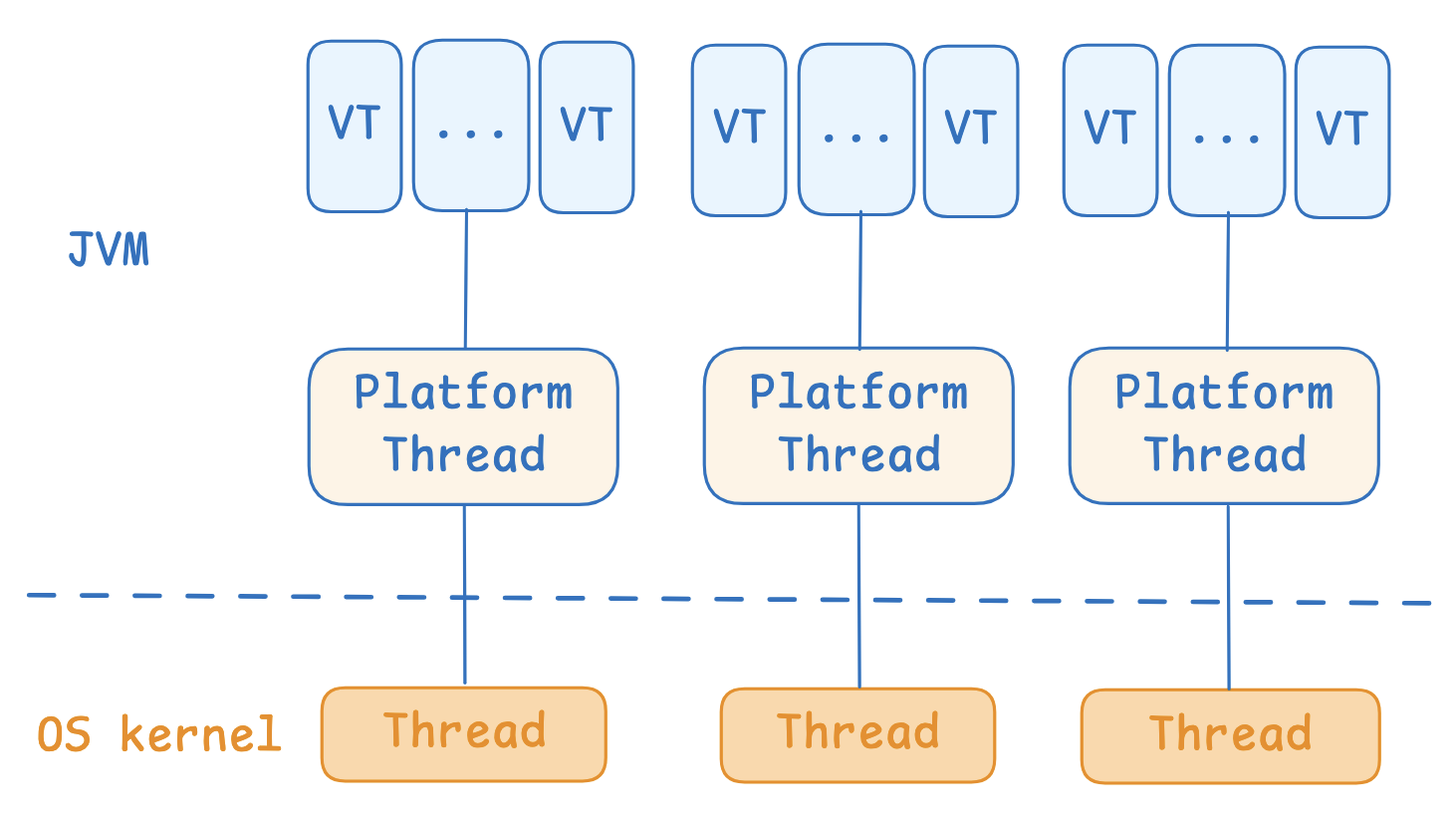
分配给虚拟线程的平台线程称为虚拟线程的载体线程(carrier thread),载体线程的信息对虚拟线程不可见,Thread.currentThread()返回的始终是虚拟线程本身。
优化版本 - 虚拟线程
聪明的小明一下就明白了,他将上面的线程池版本改成了虚拟线程版本:
Instant start = Instant.now();
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 300; i++) {
int taskId = i;
executor.submit(() -> {
System.out.printf("Task %d is running on thread %s%n", taskId, Thread.currentThread());
try {
Thread.sleep(50); // 模拟任务执行
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
System.out.printf("Task %d was interrupted.%n", taskId);
}
});
}
}
Instant end = Instant.now();
long duration = java.time.Duration.between(start, end).toMillis();
System.out.printf("任务执行完成,总花费时间: %d 毫秒%n", duration);可以看到,虚拟线程的使用方式和传统线程是类似的。
通过执行上面代码,小明惊喜地发现,虚拟线程版本只需要100多ms的执行时间,比线程池版本的速度提高了整整一个数量级。这是因为对于300个任务来说,一共开启了300个虚拟线程。因为虚拟线程非常轻量化,开销小,因此在这种场景下,即使同时创建 300 个虚拟线程,也不会对系统资源(比如内存)造成明显的压力。
其他语言的杀手锏
Go在2009年推出时,就提供了Goroutine这个杀手锏来处理IO密集型任务。Node.js 在2009年推出,采用的是事件驱动、非阻塞式I/O模型,其天生就非常适合处理IO密集型任务。而Java直到2022年的JDK19才推出虚拟线程。
如果使用Node.js来实现小明上面的功能:
const { performance } = require('perf_hooks')
async function someTasks() {
const start = performance.now()
const tasks = []
for (let i = 0; i < 300; i++) {
const taskId = i
tasks.push(
(async () => {
console.log(`Task ${taskId} is running on thread ${process.pid}`)
await new Promise(resolve => setTimeout(resolve, 50)) // 模拟任务执行
})()
)
}
// 等待所有任务完成
await Promise.all(tasks)
const end = performance.now()
const duration = end - start
console.log(`任务执行完成,总花费时间: ${duration.toFixed(2)} 毫秒`)
}
someTasks()Go和Node.js的异步模型和协程天生就非常适合处理IO密集型任务,而Java的传统线程模型则更适合计算密集型任务。Java早期的重点是“并行性”而非“并发性”,因此大量并发任务的处理一直通过多线程和并行编程模型(例如Fork/Join框架)来解决。在Java 8及之后,Java开始引入如CompletableFuture、Stream等用于处理并发和异步任务的工具,这在一定程度上弥补了其在处理IO密集型任务时与Go和Node.js的性能差距。
虚拟线程的概念在Java中要实现并不容易。它要求在Java虚拟机(JVM)中进行大量的优化和修改。Java的虚拟机本身是在操作系统的线程模型之上构建的,因此要使虚拟线程不仅能在Java层面高效运行,而且还要与操作系统层面的线程协调,这需要时间和大量的研究。